선형 회귀(단순 선형/다중 선형)
1. 단순 선형 회귀단순 선형회귀는 학창시절 배웠던 1차 함수와 비슷하다고 생각하시면 됩니다.$$ Y = \beta_1 x_1 + \beta_0 $$$$ Y = ax + b $$둘을 비교해보면 간단합니다. 앞으로는 기호들을 아
jsm-portfolio.tistory.com
이전 글에 이어서 진행하도록 하겠습니다!!
단순 선형 회귀에 대한 문제를 풀 때에는 다중공선성이나 변수선택에 대한 문제가 없습니다.
하지만 다중 선형 회귀에 대한 문제를 해결할 때 위와 같은 두 가지의 문제가 발생합니다.
그에 관한 해결책이 바로 제목에 작성한 세 가지 입니다.
- 릿지(Ridge) 회귀 : L2 정규화를 사용합니다
- 라쏘(Lasso) 회귀 : L1 정규화를 사용합니다
- 엘라스틱 넷(Elastic Net) : 릿지와 라쏘를 결합한 모델입니다.
수식을 통해 알아보겠습니다.
1. 릿지 회귀 (Ridge Regression)
$$ Loss = SSE + \lambda \sum_{j = 1}^{n}{\beta_{j}^{2}} $$
수식에 대한 설명
- 제곱합에 대해 패널티를 부여합니다.
- 회귀 계수 값을 작게 만들어 복잡도를 낮춥니다.
기능
가중치를 통해 다중공선성을 해결하는데에 많은 도움이 됩니다.
2. 라쏘 (Lasso Regression)
$$ Loss = SSE + \lambda \sum_{j = 1}^{n}{\vert\beta_{j}\vert} $$
수식에 대한 설명
- 계수의 절댓값의 합에 대해 패널티를 부여합니다.
- 회귀 계수 값을 작게 만들어 복잡도를 낮춥니다.
기능
- 변수 중요도를 가중치를 통해 변경할 수 있으므로 변수 선택에 도움이 됩니다.
3. 엘라스틱 넷 (Elastic Net)
$$ Loss = SSE + \alpha \lambda \sum_{j = 1}^{n}{\vert\beta_{j}\vert} + \frac{(1-\alpha)}{2} \lambda \sum_{j = 1}^{n}{\beta_{j}^{2}} $$
릿지와 라쏘를 결합하여 두 가지의 기능을 모두 적절하게 사용할 수 있는 모델입니다.
알파 값을 통해 둘의 비율을 조절할 수 있습니다.(0인 경우 : 릿지, 1인 경우 : 라쏘)
위의 세 가지를 코드를 통해 비교해보도록 하겠습니다!!
코드 리뷰
우선 데이터를 생성해보도록 할게요!
from sklearn.datasets import make_regression #make_regression 불러오기
from sklearn.model_selection import train_test_split
# 데이터 생성, 데이터셋 나누기 8:2
X, y = make_regression(n_samples=100, n_features=10, noise=0.1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
데이터를 만드는 라이브러리를 불러오고 해당 데이터 셋을 8:2 비율로 나눴습니다!!. random_state = 42!
그 다음 모델도 불러올게요
import numpy as np #numpy 불러오기
import matplotlib.pyplot as plt #plt 불러오기
from sklearn.linear_model import Ridge, Lasso, ElasticNet
코드를 한번 사용해보겠습니다.
# 릿지 회귀
ridge_single = Ridge(alpha=1.0)
ridge_single.fit(X_train_single, y_train_single)
y_pred_ridge = ridge_single.predict(X_single)
ridge_coefficients = ridge.coef_
# 라쏘 회귀
lasso_single = Lasso(alpha=0.1)
lasso_single.fit(X_train_single, y_train_single)
y_pred_lasso = lasso_single.predict(X_single)
lasso_coefficients = lasso.coef_
# 엘라스틱넷 회귀
elastic_net_single = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net_single.fit(X_train_single, y_train_single)
y_pred_elastic = elastic_net_single.predict(X_single)
elastic_net_coefficients = elastic_net.coef_
# 시각화
plt.figure(figsize=(12, 8))
# 원 데이터 산점도
plt.scatter(X_single, y_single, color="gray", label="Actual Data", alpha=0.6)
# 릿지 회귀 직선
plt.plot(X_single, y_pred_ridge, color="blue", label="Ridge Regression")
# 라쏘 회귀 직선
plt.plot(X_single, y_pred_lasso, color="red", label="Lasso Regression")
# 엘라스틱넷 회귀 직선
plt.plot(X_single, y_pred_elastic, color="green", label="ElasticNet Regression")
# 그래프 설정
plt.title("Ridge, Lasso, ElasticNet Regression Lines", fontsize=16)
plt.xlabel("Feature Value", fontsize=14)
plt.ylabel("Target Value", fontsize=14)
plt.legend(fontsize=12)
plt.grid(alpha=0.5)
plt.tight_layout()
plt.show()
그래프는 이렇게 나오네요!!! 엘라스틱 넷이 전체적으로 기울기가 작습니다!
그럼 실제 feature들의 기울기를 확인해볼까요?
plt.figure(figsize=(12, 8))
index = np.arange(len(ridge_coefficients))
# Coefficients 비교
plt.bar(index - 0.2, ridge_coefficients, width=0.2, label="Ridge", color='blue')
plt.bar(index, lasso_coefficients, width=0.2, label="Lasso", color='red')
plt.bar(index + 0.2, elastic_net_coefficients, width=0.2, label="ElasticNet", color='green')
# 레이블 및 제목
plt.axhline(0, color='black', linewidth=0.8)
plt.xticks(index, [f'Feature {i+1}' for i in range(X.shape[1])], rotation=45)
plt.ylabel('Coefficient Values')
plt.title('Comparison of Ridge, Lasso, and ElasticNet Coefficients')
plt.legend()
plt.grid(alpha=0.5)
plt.tight_layout()
plt.show()
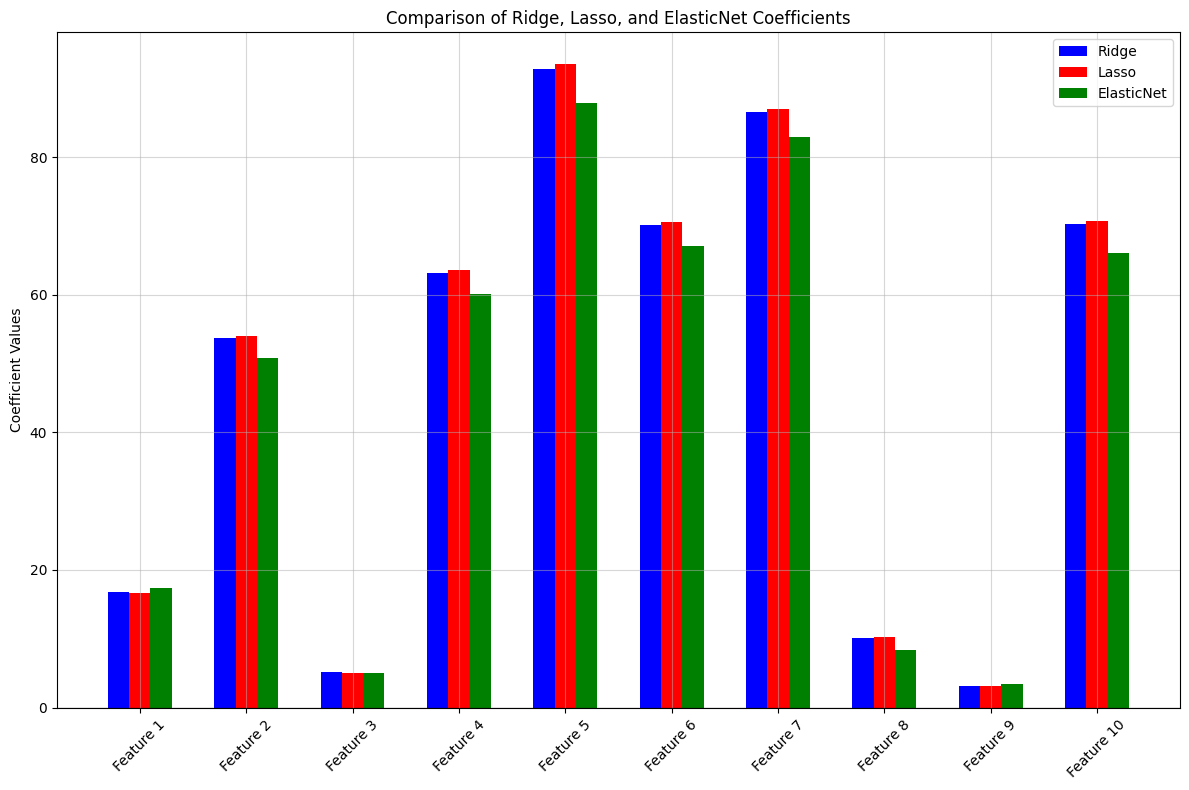
간혹 Elastic의 값이 높게 나오는 것들도 보이지만, 전체적으로 Elastic이 릿지와 라쏘보다 낮게 나오네요!!
다른 값들이나 다중 회귀 데이터를 넣어보세요!! 오늘은 여기까지 하겠습니다!
'[데이터 분석가] > [머신러닝,딥러닝]' 카테고리의 다른 글
| 로지스틱 회귀(Logistic Regression) (0) | 2025.01.23 |
|---|---|
| 서포트 벡터 머신 (Support Vector Machine) (0) | 2025.01.22 |
| 선형 회귀(단순 선형/다중 선형) (0) | 2025.01.20 |


